Center for Complexity and Self-Management of Chronic Disease
(CSCD): Core 2: Methods and Analytics Progress (2015-2016)
The main 2015-2016 accomplishments of the Methods and Analytics core
include:
I. Data Dashboard
In
this study (PMCID: PMC4520712),
we developed a mechanism to integrate dispersed multi-source data and service
the mashed information via human and machine interfaces in a secure, scalable manner.
This process facilitates the exploration of subtle associations between variables, population
strata, or clusters of data elements, which may be opaque to standard independent inspection of
the individual sources. This new platform includes a device agnostic tool
(
Data Dashboard webapp) for graphical
querying, navigating and exploring the multivariate associations in complex heterogeneous
datasets.
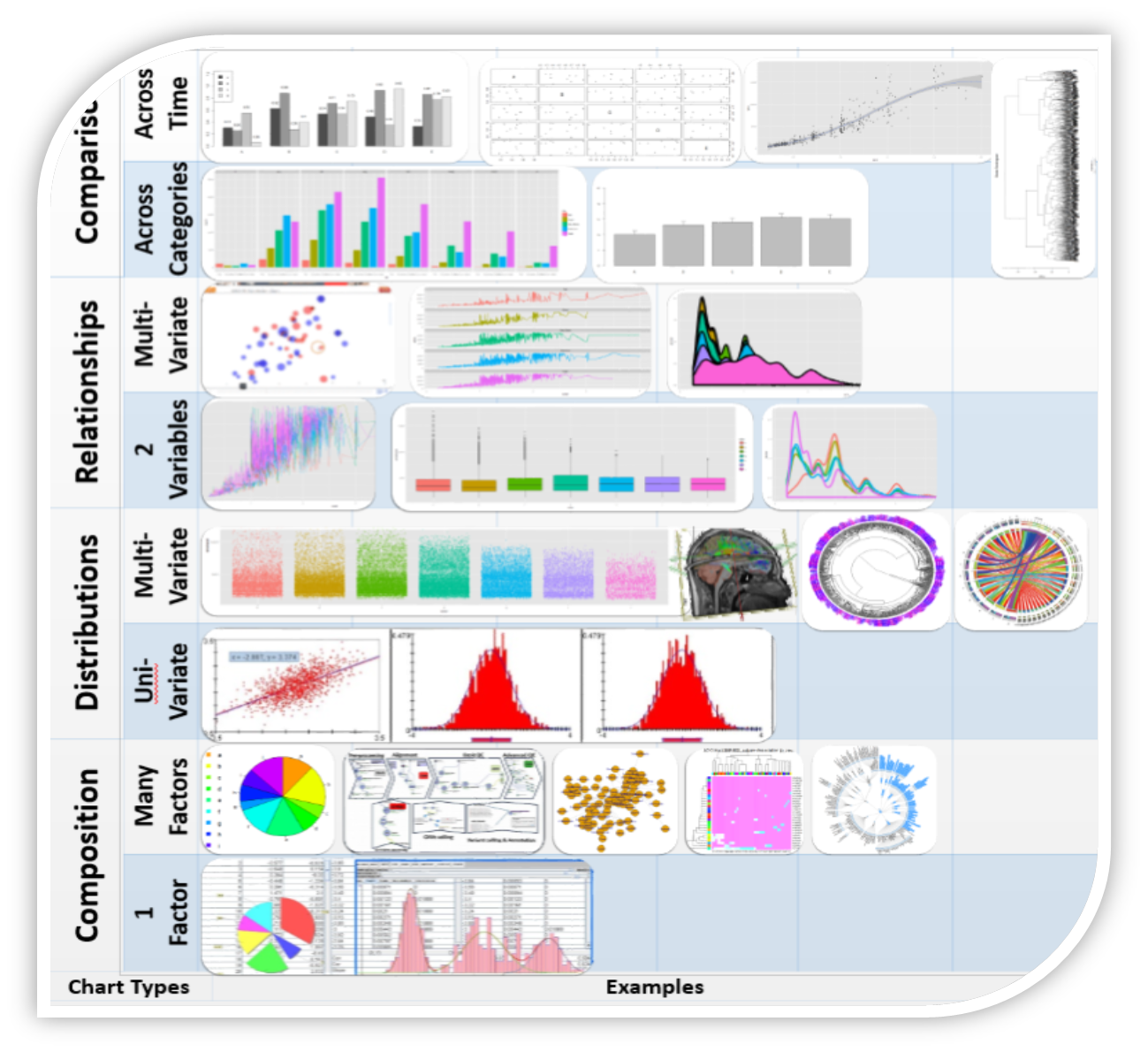
II. Data Visualizaiton
There is no fundamental theory for representation, analysis and inference. We developed
a roadmap for uniform handling, visualization and analysis of such complex data remains elusive.
This figure illustrates some of the graphical data visualization methods that we are
employing for various classes of datasets. Technical details are available
here (SMHS EBook) and
here (SMHS Canvas).
III. Predictive Big Data Analytical Methods
Managing, processing and understanding big healthcare data is challenging, costly and demanding.
Without a robust fundamental theory for representation, analysis and inference, a roadmap
for uniform handling and analyzing of such complex data remains elusive. In
this study (PMCID: PMC4766610), we
outline various big data challenges, opportunities, modeling methods and software techniques
for blending complex healthcare data, advanced analytic tools, and distributed scientific
computing. Using imaging, genetic and healthcare data we provide examples of processing
heterogeneous datasets using distributed cloud services, automated and semi-automated
classification techniques, and open-science protocols.